使用Pytorch进行模型训练
什么是 Pytorch?
PyTorch 是一个开源的深度学习框架。有以下特点:
-
动态计算图:PyTorch 使用动态计算图,这意味着你可以在运行时动态地构建、修改和执行计算图。与一些静态计算图的框架相比,这种灵活性使得调试更加容易,并且能够更自然地表达复杂的模型结构和控制流。例如,在进行模型的探索和实验阶段,你可以根据实际情况随时调整模型的结构和计算流程,而不需要重新构建整个计算图。
-
易于使用的 API:它提供了简洁、直观的 API,使得开发者能够快速上手。无论是构建简单的神经网络还是复杂的深度学习模型,PyTorch 的 API 都能让你以相对较少的代码实现。例如,定义一个神经网络只需要继承
torch.nn.Module类,并实现forward方法即可。 -
强大的 GPU 加速:PyTorch 能够充分利用 GPU 的强大计算能力,加速模型的训练和推理过程。通过将数据和模型转移到 GPU 上,可以显著提高计算速度,特别是对于大规模数据和复杂模型。你可以使用
torch.cuda模块来轻松地在 GPU 和 CPU 之间切换。
应用场景
-
计算机视觉:在图像分类、目标检测、图像分割等任务中,PyTorch 被广泛应用。许多先进的计算机视觉模型都是使用 PyTorch 实现的,如 ResNet、Faster R-CNN 等。开发者可以利用 PyTorch 提供的丰富的图像处理工具和库,快速构建和训练高效的计算机视觉模型。
-
自然语言处理:对于文本分类、机器翻译、语言建模等自然语言处理任务,PyTorch 也提供了强大的支持。它的动态计算图和灵活的 API 使得处理变长序列数据变得更加容易。同时,PyTorch 社区也提供了许多预训练的语言模型和工具,方便开发者进行自然语言处理任务的开发。
-
强化学习:在强化学习领域,PyTorch 同样具有广泛的应用。它可以与各种强化学习算法结合使用,帮助开发者构建智能体并进行训练。例如,使用 PyTorch 可以实现深度 Q 网络(DQN)、策略梯度算法等强化学习算法,用于解决各种游戏和实际问题中的决策任务。
示例
在此章节我们将给出一个简单的示例,演示如何使用 pytorch 构建一个简单的机器学习任务,主要是用来处理结构化数据(类似于二维表格数据),并基于这些数据进行分类。
这个例子模拟了一个简单的场景:一个模型根据商品的价格和评分来预测商品是否受欢迎。受欢迎的标准是价格 + 评分 > 10。我们使用生成的商品数据(价格和评分)进行模型训练,并最终测试其准确率。
前置依赖
- 完成实例的创建,需选择带有 pytorch 的镜像,实例不能为无卡模式。
下载示例代码
NOTE:在本文末尾附上源代码,如果 GitHub 拉取失败,可以直接粘贴代码。
下载 github上 的示例代码:
git clone https://githubfast.com/matrixorigin/demo.cdc.datenfab.com-docs.git
示例代码主要完成了以下任务:
-
生成数据集:随机生成 800 个训练样本和 200 个测试样本,样本包括价格和评分两项特征。标签由规则 价格 + 评分 > 10 决定,符合条件的标签为 "受欢迎"(1),否则为 "不受欢迎"(0)。
-
训练模型:通过神经网络模型对训练数据进行5轮训练,每轮训练之后打印当前的损失值。
-
测试模型:在测试集上评估模型的准确率,并打印结果。
-
单样本预测:对一个给定的商品(价格为 7.5,评分为 3.0)进行预测,模型会输出它是受欢迎还是不受欢迎。
运行代码
示例代码放置在 demo.cdc.datenfab.com-docs/static/demo 目录下。
cd demo.cdc.datenfab.com-docs/static/demo
python pytorch-demo.py
运行结果

模型在 10 个 epoch 的训练中,损失值从 从 0.5984 降到 0.4144,表明模型正在有效地学习如何通过输入特征(价格和评分)来预测目标值(是否受欢迎)。
最终测试准确率达到 81.50%,显示了模型在新数据上的表现。这个结果已经表明模型能够较��好地完成分类任务,但可以通过增加训练轮次或调整超参数来进一步提升模型的性能。
对于输入样本 [[7.5, 3.0]],模型的预测结果为“受欢迎”。根据训练数据的生成规则,该样本的标签应该为 1,因为价格和评分的和(7.5 + 3.0 = 10.5)大于 10。因此,模型正确地识别了这个样本为“受欢迎”。
使用 Tensorboard 进行模型训练监控
TensorBoard 是 TensorFlow 的官方可视化工具,可以帮助用户更好地理解和分析模型的训练过程。demo.cdc.datenfab.com 已内置这一工具,训练日志会记录在目录/root/tensorboard-logs 下。如需了解 TensorBoard 的更多信息请查看Tensorboard。
点击 Tensorboard 跳转到 Tensorboard 面板。
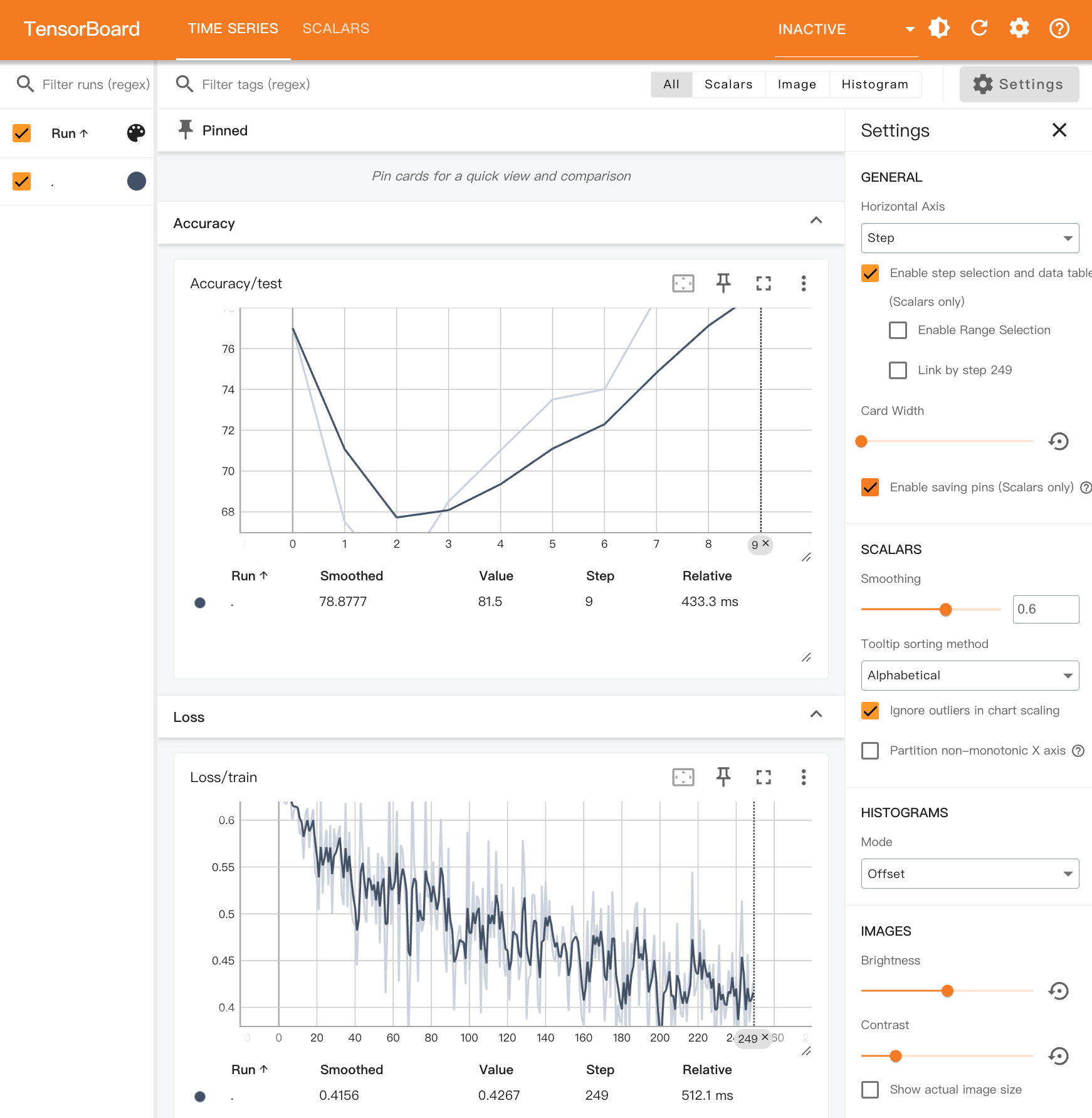
-
Loss/train:记录每个 batch 的训练损失。
-
Accuracy/test: 记录每个 epoch 结束时模型在测试集上的准确率。
通过 TensorBoard,你可以直观地观察模型的学习进展,分析训练过程中的性能变化并作出相应的调整。
示例代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
from torch.utils.tensorboard import SummaryWriter
# 1. 生成模拟数据集
def generate_data(num_samples):
# 随机生成商品的价格和评分
prices = np.random.uniform(1.0, 10.0, size=(num_samples, 1)) # 商品价格范围为 1.0 到 10.0
ratings = np.random.uniform(1.0, 5.0, size=(num_samples, 1)) # 商品评分范围为 1.0 到 5.0
# 标签: 假设价格 + 评分 > 10 的商品被认为是 "受��欢迎"(标签为 1),否则为 "不受欢迎"(标签为 0)
labels = (prices + ratings > 10).astype(int).reshape(-1)
# 将数据转换为 PyTorch 张量
X = torch.tensor(np.hstack((prices, ratings)), dtype=torch.float32)
y = torch.tensor(labels, dtype=torch.long)
return X, y
# 2. 定义简单的神经网络模型
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(2, 32) # 输入层: 2 个特征(价格和评分),32 个神经元
self.fc2 = nn.Linear(32, 2) # 输出层: 2 个类别(受欢迎或不受欢迎)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x) # 输出原始分数,不需要 softmax
return x
# 3. 训练函数
def train(model, train_loader, test_loader, criterion, optimizer, device, writer):
model.train() # 切换到训练模式
for epoch in range(10): # 训练 20 个 epoch
total_loss = 0
for i, (data, labels) in enumerate(train_loader):
data, labels = data.to(device), labels.to(device)
optimizer.zero_grad() # 梯度清零
outputs = model(data) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新权重
total_loss += loss.item() # 累加损失
# 将损失记录到 TensorBoard
writer.add_scalar('Loss/train', loss.item(), epoch * len(train_loader) + i)
average_loss = total_loss / len(train_loader)
# 测试模型并输出准确率
accuracy = test(model, test_loader, device, writer, epoch)
print(f'Epoch [{epoch + 1}/10], Average Loss: {average_loss:.4f}, Accuracy: {accuracy:.2f}%')
# 4. 测试函数
def test(model, test_loader, device, writer, epoch):
model.eval() # 切换到评估模式
correct = 0
total = 0
with torch.no_grad(): # 不计算梯度
for data, labels in test_loader:
data, labels = data.to(device), labels.to(device)
outputs = model(data)
_, predicted = torch.max(outputs, 1) # 获取每个样本的预测值
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
# 将准确率记录到 TensorBoard
writer.add_scalar('Accuracy/test', accuracy, epoch)
return accuracy
# 5. 对某个样本进行分类预测
def predict(model, sample, device):
model.eval() # 切换到评估模式
with torch.no_grad(): # 预测时不需要计算梯度
sample = torch.tensor(sample, dtype=torch.float32).to(device)
output = model(sample)
_, predicted = torch.max(output, 1) # 获取预测结果
return predicted.item()
# 主函数
def main():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 创建 TensorBoard 写入器
writer = SummaryWriter(log_dir='/root/tensorboard-logs')
# 生成随机训练和测试数据
X_train, y_train = generate_data(800) # 生成800个训练样本
X_test, y_test = generate_data(200) # 生成200个测试样本
# 将数据封装为TensorDataset
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
# 使用DataLoader加载数据
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 创建网络模型
model = SimpleNet().to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.01) # 使用随机梯度下降优化器
# 训练模型
train(model, train_loader, test_loader, criterion, optimizer, device, writer)
# 对某个样本进行分类预测
sample = [[7.5, 3.0]] # 商品的价格为7.5,评分为3.0
prediction = predict(model, sample, device)
print(f'对于样本 {sample} 的预测结果为: {"受欢迎" if prediction == 1 else "不受欢迎"}')
# 关闭 TensorBoard 写入器
writer.close()
if __name__ == "__main__":
main()